GPUͨ�ü��㷢չ��ͷѸ��
�������Կ�Ƶ��8��27�� ���ڵ��Կ��г���ͬ�ʻ��Ѿ����ص���ʲô�ز��أ��������ǰ忨����֮����Կ����ܻ���û���𣬶���ͬ��λ��N����A���ڲ�ͬ��Ϸ�еı���Ҳ���ѷ�ʤ��������Ϸ��������Ծ���

����NVIDIA��AMD�ľ�����ʼ������Ϸ����ǿ�����ܺ�Ӧ�ã�������3D��PhysX����Ƶ�ȿ�ʼ���������������Щ���ܶ���������������CUDA��Stream�ķ��ٷ�չ������OpenCL��DirectComputeͨ�ü������ʹ��NVIDIA��AMD����һ����·��չ�����µľ����������м��㡣
������GPU�Ѿ��ڿ�ѧ�о��ͳ�����������ȡ��ͻ���Խ�չ������������֧��CUDA��GPU�Ѿ��鲼ȫ������������������Ա����ѧ��ʿ���о���Ա��������CUDA̽��������������У�����ͼ�����Ƶ�༭����������ѧ�ͼ��㻯ѧ��������ѧģ�⡢CTͼ�����顢����������������Լ��������ࡣ�����������������ͻ���ͽ��ܴ�̶���Ҳ�ǵ�����ǿ���GPU���ˡ�

���Կ�����Ȥ�����Ѷ�֪����ͨ�ü���֮����������ţ�����ԭ�������Կ�����GPU�Ķ������������൱�����ٺ��ģ��ܹ���GPUǿ��IJ��и������������ǽ���ӵ�и�λ�����ĵ����봦����CPU��������ġ���ͨ�ü��㼼�����Է���GPU�ij�����������������ٶ������һЩӦ�ó�����ٶȿ����������������ʮ������ԭ����Ϊ���������������ɵ������ÿ��С�
���ڼ��á��칫�����ϣ�����GPU���ٵ�����ҲԽ��Խ�࣬��Щ�����еĿ�������ת�룬�еĿ���������ǿͼ����Ƶ�Ļ��ʣ��еĿ��Խ�2D��Ӱת����3D���еĻ������ܹ���ͱ༭��Ƭ����
AMD��NVIDIAͨ�ü������
��������GPGPU���ͬ���ǣ�CUDA��һ�������Ľ��������������API��C�������ȣ��ܹ������Կ����ĵ�Ƭ��L1 Cache�������ݣ�ʹ���ݲ��ؾ����ڴ�-�Դ�ķ������䣬shader֮���������Ի���ͨ�ţ������ݵĴ洢Ҳ����Լ��������GPGPU��������ʽ����ȡ���������Գ������stream out������������ԣ�����͵����Ӿ���PhysX����������Ч��PhysX������Aegia��˾�Ƴ���Ӳ�����������ټ�����NVIDIA�����չ�֮���ͨ��CUDA������PhysX�����������Կ��е�shader��Ԫ�е�����������Ч�����㡣

����Stream������AMD���ƿ����Կ������ٸ�ƽ�д������ģ�Ϊ����һ����;��Ӧ�ô������ٵ�Ч����������������ƽ̨�����ɴ������ÿ�����ܣ���ʵ����һ���ǰ���������AMD���ص�����������Ԫ��ơ�
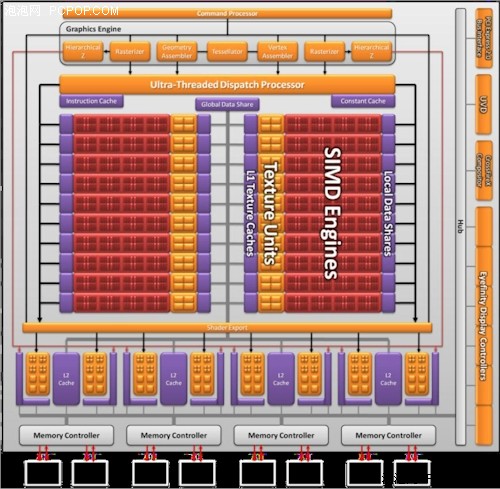
GF100��512��CUDA���Ķ�����IEEE 754-2008�����㷨(CypressҲ�����)��������32λ�����㷨���������ڹ�ȥֻ��ģ��ģ���ʵ�Ͻ��ܼ���24-bit�����˷���ͬʱȫ������Ļ��л����ۼ�����(Fused Multiply-Add/FMA)������˫���ȸ���(FP64)���ܴ����������ִֵ���ʿ��Դﵽ�����ȸ���(FP32)��1/2������ȥֻ��1/8��AMD��R600��ʼ�����ڵ�Cypress���Ķ���1/5��û�����κα仯��
�������۵��ֲ�ʽ���㣺N�����ƾ�
��ʵҵ���һ��GPUͨ�ü������������û���ѧ���㣬��������˹̹����ѧ������Folding @ Home�ֲ�ʽ���㣬����֧��ATI�Կ�����NVIDIA�����߾��ϣ�ĿǰN�����������������Ѿ���Խ������CPU֮�ͣ�A��Ҳ������

Folding@home��һ���о��������۵������ۡ��ۺϼ��ɴ��������ؼ����ķֲ�ʽ���㹤�̡��ʼF@H��֧��CPU�����������˶�PS3��Ϸ����֧�֣���ͬ����ʹ�����õ�CELL�����������㡣F@H��ATI�ļ���ΪGPU���㷭�����µ�һҳ�����F@H�ڶ���GPU�ͻ����Ѿ��ܹ�֧��ATI��NVIDIA��ȫϵ��DX10 11 GPU

���Fermi���ĵ�ƽ���������ƣ���Folding@Home�����°汾GPU3��רΪ��һ��Fermiϵ���Կ����裬��һ������Fermi���ļܹ�֮���ơ�
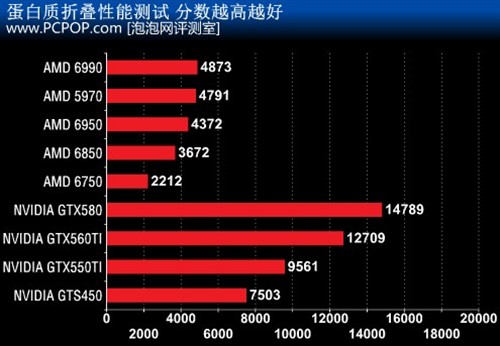
�ݹٷ����ܣ��°�ĵ������۵������ٶȼ��ȶ����Ѿ������ߣ����Ҽ�����ӿ�ѧ������Ŀ��ϣ���ܼ�Fermi���ĵļܹ����ƣ��ӿ졶Folding@Home���ڵĸ�������㡣Shader��Ƶ�ʶ�Ӱ������Ч�ܷdz�������NVIDIA��������AMD�ܶࡣ
GPU�����ƽ����룺A��ңң����
��ʧ������һ�������൱���յ��£����������ǹ����ĵ�����������ɵĽ�Ǯ��ʧ����ʮ�֡����ߡ�����ο�ݸ�Ч���һ������Ǽ����¡�����GPU�ķ�չԽ��Խǿ�ƣ�ͨ�����������Ѿ�Զ����CPU����CPU����������ȴ�����ģ������ܹ����ӳ�GPUǿ���ͨ�������������ػ��������ƽ������ʱ�䡣
GPU������ʾ���ġ����ࡱ��Ҳ���൱��CPU�ڵ����е����ã��������˸��Կ��ĵ��κʹ������⣬�����Ŵ��ģ�IJ��м��������������ÿ�����Ա���ȳ��������õ����Ѽ���רҵ���ļ���Ӧ�ó���������NVIDIA��CUDA������AMD��Stream���㣬�����ڶ��������������ġ�

����������Elcomsoft��Ʒ��ADVanced Office Password Recovery����һ��ͬʱ֧��CPU��GPU��Office����ָ�����������֧��32��CPU���ں˺�8��GPUͬ�����У�Ҳ����ָ��ȫ�������Dz���CPU/GPU���Ľ��лָ�����Ĺ�����
���������ǹر�����CPU���ģ���ȫ��GPU�����������ƽ�һ����6λ���ּ��ܵ�Word�ļ���
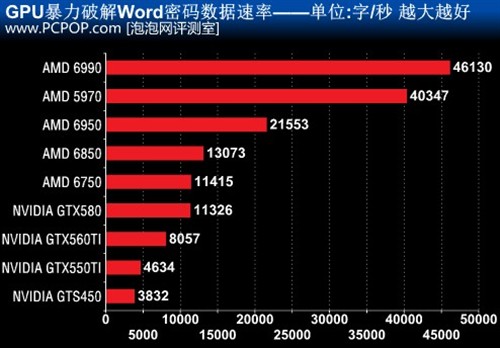
�����ƽ�����������������dz����С�AMD��GPU����SIMD�ܹ����Ӵ�������������ңң������NVIDIA GPU��
������Ƶת�룺N���Կ���A��
Cyberlink��Ѷ���Ƽ������´�������PowerDVD���Ŵ�Ҷ��dz���Ϥ����Ϊһ��רע��Ƶ���ý������������̣�Cyberlink����ǰ�Ƴ���һ��רҵ�Ŀ�����Ƶת����������MediaShow Espresso����Ҫע�����MediaShow(��������)��һ����Ƶ�༭��������MediaShow Espresso������Ƶת��������

���ڱ��������������ɣ�����MediaShow Espressoȴ�����Ķ���֮�������ǵ�һ��ͬʱ֧��CUDA��Stream���ٵ���Ƶת������������֮��������Intel Core i7�������ij��̼߳�SSE4ָ������Ż���������۴�CPUת�뻹��GPU���٣����ٶȱȴ�ͳ������Ҫ�졣
������Ƶ�ļ�Ϊ����Ϊ3��42������22M��H.264�����M2TS�ļ������������Ǵ�GPU������GPU����ѡ�������빤������GPU����ɡ�
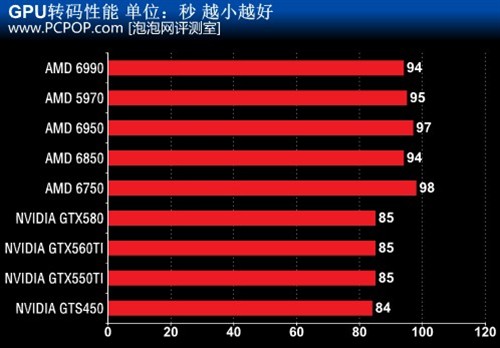
���Կ�����GPU��Ƶת��ʱ��CPU��GPU��Ҫ�μӼ��㣬����GPU����Ҫ��ȫ�������Ը߶�GPU���ж�GPU�������Dz��ġ���������N����CUDA����Ҫ����A����Stream���ܡ�
ֵ��ע����ǣ����β���ʹ�õ���ͬʱ֧��CUDA��Stream��MediaShow Espresso���в��ԣ����ʹ�ý�֧��CUDA��MediaCoder�����Ļ���N������Ƶת���ٶȻ��ܸ��죬�ⷽ��A���������ܻ�������֧�ֶȶ�����N����
DirectCompute�������ܣ�A����ռ����
ComputeMark�ɽݿ�Ӳ������Ϸ��վCzechGamer.com��Robert Varga���������������ǻ���Jan Vlietinck��Fluid3D Demo�������ܹ�ʹ�Կ�ռ���ʴﵽ99%����CPUռ���ʽ�0-1%��������CPU������ɶԲ��Գɼ���Ӱ�졣ͬʱ���������й��IJ����Ĺ��ܣ�����ʱ����������趨��
ComputeMark��Ҫ�ڴ�DX11���������У�����Windows 7 32/64λ����ϵͳ��DX11 API��DX11�Կ���

���ս���ܺ�г����ȻA�������۸������������ܸߣ�����DirectCompute���۲��Ե��У�ͬ�����A��������N���߶��١���ΪDirectCompute�ֽ���Ҫ��������Ϸ����ʹ�ã�������岻�Ǻܴ�
Bitcoin�ڿ����ܲ��ԣ�A����������
����������˽���رҵĻ�����������ǰ�������ǵ��������¡��һ�Ҳ��Ǯ���������Կ��ڿ���Ԫ���������ֱ�����ò������ݣ�
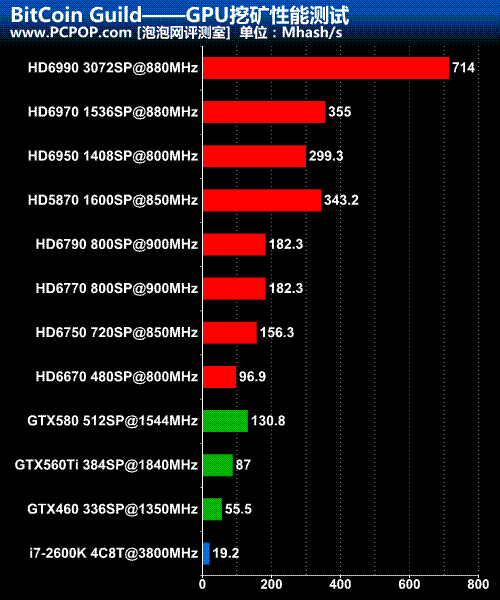
�������������Ҫ������
1. HD6990ӵ������GPU������Ƶ���뵥���ĵ�HD6970��ȫ��ͬ�������ڿ��������÷�������ʵ��HD6990������Ҫ�������ھ������������GPUһ����㡣
2. AMD�ϴ�HD5870���������Զ���HD6970��������Ƶ���Եͣ����������콢�������ڿ����ܲ�ࡣҪ֪��VLIW4�ܹ���HD6970��Ϸ����Ҫǿ��VLIW5�ܹ���HD5870�����ڿ������ƺ�ֻȡ�������۸����������������ܹ���Ч�ʺ���ϵ��
3. Barts���ĵ�HD6790ӵ��256Bit�Դ�λ������128Bit��HD6770��һ���������ߵ��ڿ�������ȫ��ͬ�������Դ�λ��Ƶ�ʶ�����û���κ�Ӱ�죬Ӱ�����ܵ�Ψһ���ؾ�����������������Ƶ�ʡ�
4. NV��������GTX580������HD6750����Ҫ��CPUǿ�ܶ࣬�Ͼ���Ҳ�����ٿź��ġ�
��ΪʲôA����N���IJ�����֮���أ����ر��ھ������õ���SHA-256���������������Ұ�ȫ�ַ�����һ�ְ�ȫɢ�к�����һ�����������������ܡ������㷨����д���32λ����ѭ���������㣬���������AMD GPU�������ͨ����һӲ��ָ��ʵ�֣�����NVIDIA GPU������Ҫ����Ӳ��ָ����ģ�⣨2��+1�ӣ�������һ����ΪAMD���������1.7������Ч�����ƣ���Լ1900ָ����ִ��SHA-256ѹ��������������NVIDIA�Ĵ�Լ3250ָ���
���һ����AMD�ϸߵĸ������������ټ����㷨Ч�����ƣ�AMD GPU�������ƽ�����ر��ھ�ʱ�����ܣ������NVIDIA GPU��3�����ϣ�
�ܽGPU��δ��������Ϸ���Ǽ���
ͨ��ǰ�漸�ͬ���͵�ͨ�ü���Ӧ��������A����N��֮������ܲ�����൱��ģ����Ҷ��������Ǽ������ϵIJ�ࡣA���ֲ�������������ʱ��ȷʵ��Ч��������ʱ����Ҫ��������N��������˫����3D��Ϸ�к�г���ı��ֽ�Ȼ�෴��
������ֵ�����һ��������˫����Ȼ��ͬ�ļܹ�����ɵģ���һ�����Dz�ͬӦ�õ��㷨��ͬ�����ܻ�Ƚϡ�ƫ����ijһ�ּܹ������գ���Ҫ��˭�������Ż��������úã�˭����ʤ����Ŀǰ����CUDA����ռ�����Ե��Ϸ磬�Ѿ��кܶ೬��������䱸��NVIDIA Tesla���ٿ���CUDA��Ӧ����������Ҫ��Stream��ܶ�ġ�

����CUDA��Stream��ǿ������OpenCL��DirectCompute��˭��Ц�����GPU�ĵ�λ��Ȼ��Ѹ�������������������Ҫ��������ȡ��ͻ�ƣ�ʹ��GPU+CPU���칹�ܹ���Ψһѡ��δ�������ܼ����Ѿ��벻��GPU��֧���ˡ�
NVIDIA��ATI��3D��Ϸս������ͨ�ò��м���������˭��Ц��������ڻ��Ǹ�δ֪����

������ͨ�û���˵���Կ��Ѿ�������һ�鵥����3D��Ϸ���ٿ�������ƵӦ��Ϊ�����ĸ����ܼ����������Ȳ���GPUͨ�ü���Ĵ��ţ�δ�������и����������ʹ��GPUǿ����������������٣�CPU��GPU�ĵ�λ�����ͬ����Ҫ�����ڣ��������һ�����ر�ϲ������Ϸ�������Կ��������������ܶ����Ϸ���ˣ�Ҳ����뵽�����Կ�������
[ҳ��1] [ҳ��2] [ҳ��3] [ҳ��4] [������ҳ]

